Tugas GSLC (Natural Language Processing)
1. Text classification
Text Classification sering dengan disebut kategorisasi yaitu diberikan teks serupa, yang tentukan termasuk di kelas mana dari kumpulan yang sudah didefinisikan sebelumnya.
Contoh dari klasifikasi teks:
– Identifikasi bahasa dan gaya klasifikasi
-Analisis perasaan (klasifikasi bioskop atau produk pandangan ulang sebagai positif atau negatif) dan
-Deteksi spam (klasifikasi pesan email sebagai spam atau bukan-spam).
Cara lain berfikir tentang klasifikasi adalah sebagai masalah kompresi data. Algoritma lossless compression mengambil urutan symbol, mendeteksi pola yang berulang, dan menulis diskripsi urutan yang lebih ringkas dari aslinya.
Contohnya, teks “0.142857142857142857″ dapat dikompres dengan Algoritma Kompresi yang bekerrja dengan membangun kamus urutan dari teks, dan kemudian mengacu ke entri dalam kamus. Contoh di atas hanya satu entri kamus, “142857.“
Dalam efeknya, algoritma kompresi membuat model bahasa. Algoritma LZW secara khusus langsung memodel distribusi probabilitas maximum-entropy. Mengerjakan klasifikasi dengan kompresi, pertama kali kita menyatukan semua spam training messages dan mengkompresinya.
Didalam Text classification terdapat 3 tahap yaitu:
Preprocessing
Tahap pertama dalam text classification adalah dokumen preprocessing yang terdiri dari 3 bagian yaitu ekstrasi term,seleksi term dan representasi dokumen.
Ekstrasi Term
Ekstrasi term dilakukan untuk menentukan kumpulan term yang mendeskripsikan dokumen.
Seleksi Term
Jumlah term yang dihasilkan pada feature ekstrasi dapat menjadi suatu data yang berdimensi cukup besar. Karena dimensi dari ruang feature merupakan bag-of-words hasil pemisahan kata dari dokumennya. Untuk itu perlu dilakukan feature selection untuk mengurangi jumlah dimensi.
Representasi Dokumen
Supaya teks natural language dapat digunakan sebagai inputan untuk metode klasifikasi maka teks natural language diubah kedalam representasi vektor.
Training Phase
Tahap kedua dari text classification adalah training. Pada tahap ini system akan membangun model yang berfungsi untuk menentukan kelas dari dokumen yang belum diketahui kelasnya. Tahap ini menggunakan data yang telah diketahui kelasnya (data training) yang kemudian akan dibentuk model yang direpresantasikan melalui data statistik berupa mean dan standar deviasi masing-masing term pada setiap kelas.
Testing Phase
Tahap terakhir adalah tahap pengujian yang akan memberikan kelas pada data testing dengan menggunakan model yang telah dibangun pada tahap training. Tujuan dilakukan testing adalah untuk mengetahui performansi dari model yang telah dibentuk. Dengan beberapa parameter pengukuran yaitu akurasi, precision, recall, dan f-measure.
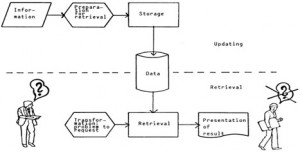
2.Information Retrieval
Information Retrieval merupakan suatu pencarian informasi (biasanya berupa dokumen) yang didasarkan pada suatu query (inputanuser) yang diharapkan dapat memenuhi keinginan user dari kumpulan dokumen yang ada. Contoh yang paling sering di gunakan dalam information retrieval adalah mesin pencari(search engine) yang ada pada www(world wide web)
Sedangkan, definisi query dalam Information Retrieval menurut referensi merupakan sebuah formula yang digunakan untuk mencari informasi yang dibutuhkan oleh user, dalam bentuk yang paling sederhana, sebuah query merupakan suatu keywords (kata kunci) dan dokumen yang mengandung keywords merupakan dokumen yang dicari dalam IR.
Tujuan dari sistem IR adalah memenuhi kebutuhan informasi pengguna dengan me-retrieve semua dokumenyang mungkin relevan, pada waktu yang sama me-retrieve sesedikit mungkin dokumen
yang tak-relevan. Sistem ini menggunakan fungsi heuristik untuk mendapatkan
dokumen-dokumen yang relevan dengan query pengguna. Sistem IR yang baik memungkinkan pengguna menentukan secara cepat dan akurat apakah isi dari dokumen
yang diterima memenuhi kebutuhannya. Agar representasi dokumen lebih baik,
dokumen-dokumen dengan topik atau isi yang mirip dikelompokkan bersama-sama
Information retrieval (disingkat IR) dapat digolongkan sbb :
A Corpus of Documents
Setiap sistem harus ditentukan jika ingin diperlakukan sebagai apa dalam document:apakah sebagai paragraf, halaman, atau multipage teks.
Queries posed in a query language
Queri yang dimiliki bahasa query. Query menetapkan apa yang ingin diketahui user. Bahasa query dapat hanya berupa daftar kata-kata, seperti [AI book]; atau dapat menentukan susunan kata yang harus berdekatan.
A result set
Kumpulan hasil. Subset dari dokumen dimana sistem IR mempertimbangkan relevan terhadap query. Dengan relevan, diartikan sepertinya digunakan oleh pemilik query, untuk informasi khusus yang dibutuhkan untuk ekspresi query.
A presentation of result test
Presentasi dari kumpulan hasil. Dapat sesederhana daftar ranking dari judul dokumen atau rumit seperti peta warna yang berputar dari kumpulan hasil yang diproyeksikan ke 3-dimensi, digambarkan dalam dispaly 2-dimensi.
3.HITS ALGORITHM
HITS (Hyperlink-Induced Topic Search)Algorithm
Hal ini hampir sama dengan algoritma PageRank, tapi HITS tidak menghitung jumlah link di halaman, tapi melihat-lihat link yang ditemukan, jika sesuai dengan tujuan link, kata-kata yang lebih tepat antara link asal ke link tujuan akan semakin tinggi nilai otoritas nya dalam halaman.
Ide dasar dibalik algoritma ini adalah bahwa semua halaman web di internet dikategorikan ke dalam dua kelompok yang disebut Hub dan Authoritas. Hub menentukan halaman web yang telah keluar ke suatu link yang merupakan halaman web penting lainnya dan authoritas menentukan halaman web yang memiliki link masuk dari halaman web penting lainnya.
Pengaplikasian algoritma hits adalah
Search engine querying(Kecepatan merupakan suatu masalah)
Mencari komunitas web
Mencari halaman web terkait
Mengisi kategori dalam direktori web
Menganalisis suatu kutipan
Langkah langkah Algoritma HITS
1.Kumpulkan halaman t atas (Misal t = 200) berdasarkan permintaan input,hal ini dinamakan set root.
2.Turunkan akar ditetapkan menjadi basis dan ditetapkan sebagai berikut, untuk semua halaman p yang di set root
-Tambahkan akar mengatur semua halaman yang menunjuk ke p
-Tambahkan akar set up-to q untuk halaman yang mengarah ke p (misal q = 50).
3.Hapus semua link dalam situs web yang sama di set dasar menghasilkan sub-grafik terfokus
4.PROLOG
Prolog adalah bahasa didasarkan pada urutan pertama logika predikat. (Akan melakukan introduce dan revisi).
Kita dapat menyatakan beberapa fakta dan beberapa aturan, kemudian mengajukan pertanyaan untuk mencari tahu apa yang benar.
Prolog dapat kembali lebih dari satu jawaban untuk sebuah pertanyaan.
Ia memiliki built in metode pencarian untuk pergi melalui semua aturan dan fakta yang mungkin untuk mendapatkan semua jawaban yang mungkin.
Metode pencarian “Depth first search” dengan “backtracking”.
contoh:
likes(john, mary).
tall(john).
tall(sue).
short(fred).
teaches(alison, artificialIntelligence).
Pengaplikasian dari prolog contoh nya:
– Sistem Pakar (Expert System)
Program menggunakan teknik pengambilan kesimpulan dari data-data yang didapat, layaknya seorang ahli.
– Pengolahan Bahasa Alami (Natural Languange Processing)
Program dibuat agar pemakai dapat berkomunikasi dengan komputer dalam bahasa manusia sehari-hari, layaknya penterjemah.
– Robotik
Prolog digunakan untuk mengolah data masukanyang berasal dari sensor dan mengambil keputusan untuk menentukan gerakan yang harus dilakukan.
– Pengenalan Pola (Pattern Recognition)
Banyak digunakan dalam image processing , dimana komputer dapat membedakan suatu objek dengan objek yang lain.
– Belajar (Learning)
Prolog gunakan untuk mempelajari,mengamati dari hal hal yang pernah di lakukan.





